 LoveCTO
LoveCTO我们在上一篇中介绍了ubuntu搭建solr《ubuntu搭建solr-8.11.3并图形界面创建core》,今天我们来看看solr的中文分词。
未添加中文分词时的效果如下:
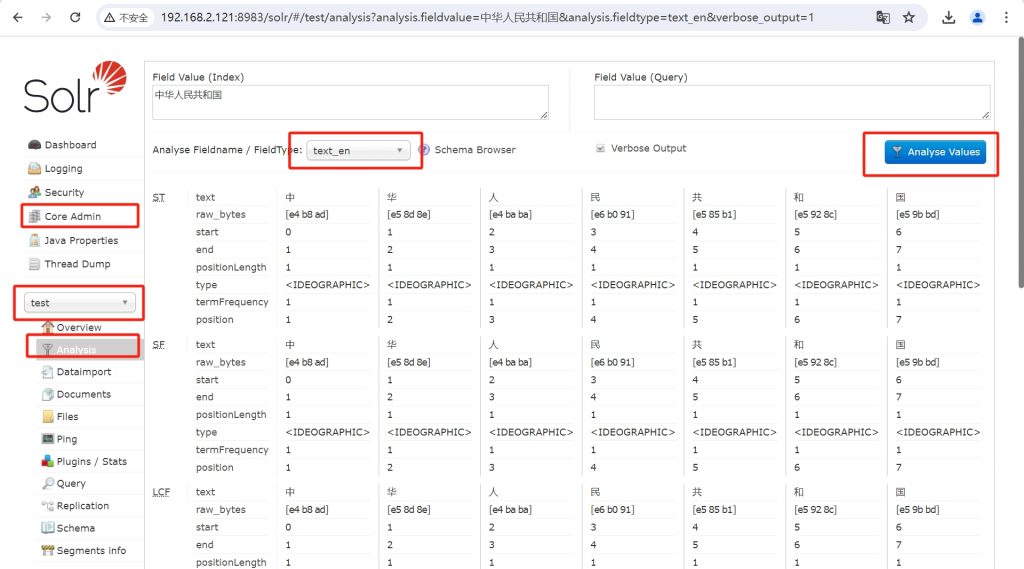
未使用IK分词
进入如下网址,下载ik-analyzer
https://mvnrepository.com/artifact/com.github.magese/ik-analyzer
我选择最新版本8.5.0,ik-analyzer版本最好与solr版本对应。下载ik-analyzer-8.5.0.jar后,将其放在如下目录:
solr-8.11.3/server/solr-webapp/webapp/WEB-INF/lib
编辑文件:“solr-8.11.3/server/solr/test/conf/managed-schema”
vi managed-schema
添加如下内容后保存退出。
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
进入目录“solr-8.11.3/server/solr-webapp/webapp/WEB-INF”,看是否有classes目录,如果没有执行如下命令创建:
mkdir classes
在个人电脑解压”ik-analyzer-8.5.0.jar”,找到”ext.dit”、“IKAnalyzer.cfg.xml”、“stopword.dic”三个文件并将它们上传到刚刚创建的classes目录下。
进入bin目录重启solr
./solr restart -force
使用ik分词后效果:
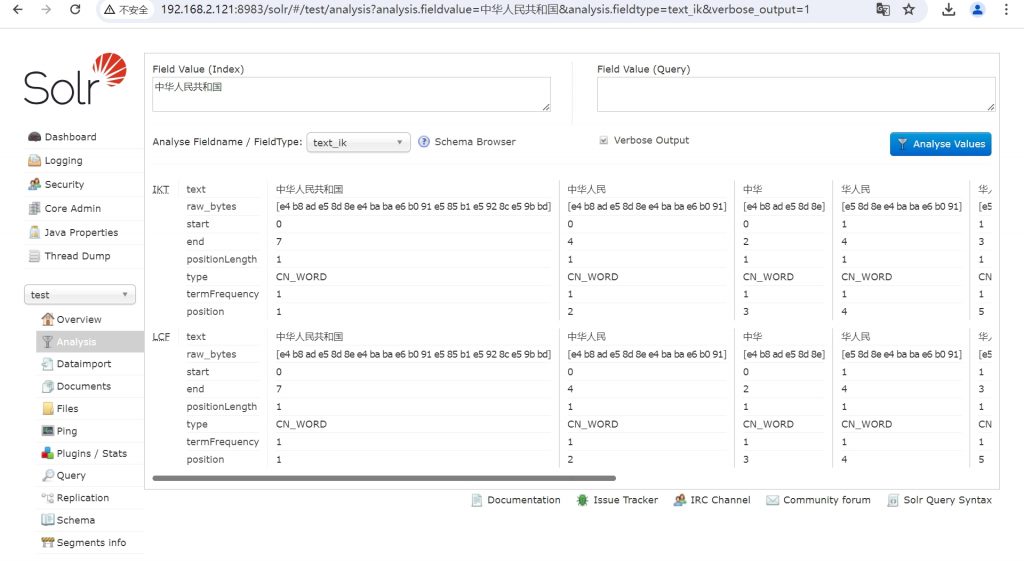
IK分词效果
“ext.dit”中可以添加用户自定义的分词,每个词用回车分隔。
修改classes下的ext.dic,添加自定义词语“民共”,重启后再执行IK分词,发现,分词中有了“民共”。
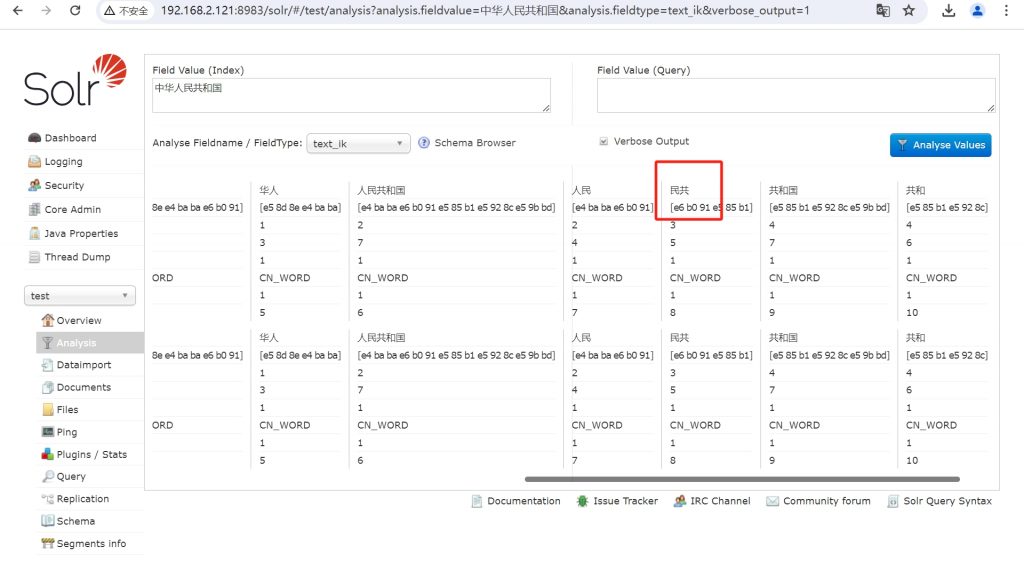
IK分词2


